Portfolio Optimization: Simple versus Optimal Methods
Membership required
Membership is now required to use this feature. To learn more:
View Membership BenefitsAdvisor Perspectives welcomes guest contributions. The views presented here do not necessarily represent those of Advisor Perspectives.
Our whitepaper “The Optimization Machine: A General Framework for Portfolio Choice” presented a logical framework for thinking about optimal methods of portfolio formation given specific assumptions regarding expected relationships between risk and return. We explored the fundamental roots of common portfolio weighting mechanisms, such as market cap and equal weighting, and discussed the rationale for several risk-based optimizations, including Minimum Variance, Maximum Diversification, and Risk Parity.
For each approach to portfolio choice we examined the conditions that would render the choice mean-variance optimal. For example, market cap weighting is mean-variance optimal if returns are completely explained by CAPM beta, or in other words, if all investments have the same expected Treynor ratios. Minimum variance weighted portfolios are optimal if all investments have the same expected return, while Maximum Diversification weighted portfolios are optimal if investments have the same Sharpe ratios.
The Portfolio Optimization Machine framework prompts questions about how well academic theories about the relationships between risk and return explain what we observe in real life. While academics would have investors believe investments that exhibit higher risk should produce higher returns, we do not observe this relationship universally.
For instance, we show that both the Security Market Line, which expresses a relationship between return and stock beta, and the Capital Market Line, which plots returns against volatility, are either flat or inverted for both U.S. and international stocks over the historical sample. In other words, stock returns are either independent of, or inversely related to risk.
We also examined the returns to major asset classes, including global stocks, bonds, and commodities. For asset classes, there appears to be a positive relationship between risk and return, at least when returns are analyzed across different macroeconomic regimes. Normalized for inflation and growth environments, stocks and bonds appear to have equal Sharpe ratios in the historical sample.
The Sharpe ratio of diversified commodities has been about half of the Sharpe ratio observed for stocks and bonds since 1970 when conditioned on regime. However, we highlight that our analysis may produce bias against commodities, given that there were few regimes that would have been favorable to commodities in our historical sample. With such a small sample size, we believe it is premature to reject the hypothesis that commodity risk should be compensated at the same rate as risk from stocks and bonds.
Our whitepaper presented a great deal of theory, and offered guidance from history about the nature of the relationship between risk and return. Armed with this guidance, we can invoke the Optimization Machine decision tree to make an educated guess about optimal portfolio choice for different investment universes.
We show that the Optimization Machine is a helpful guide for optimal portfolio formation, but that the relative opportunity for optimal versus naive methods depends on size of the diversification opportunity relative to the number of assets in the investment universe. We instantiate a new term, the “Quality Ratio” to measure this quantity for any investment universe1.
Data and methodology
In this article we put the Optimization Machine framework to the test. Specifically, we make predictions using the Optimization Machine about which portfolio methods are theoretically optimal based on what we’ve learned about observed historical relationships between risk and return. Then we test these predictions by running simulations on several datasets.
We model our investigation on a well-known paper by (DeMiguel, Garlappi, and Uppal 2007) titled “Optimal Versus Naive Diversification: How Inefficient is the 1/N Portfolio Strategy?”, which discussed some of the major technical issues that complicate the use of portfolio optimization in practice. The authors also present the results of empirical tests of various portfolio optimization methods on several datasets to compare the performance of optimal versus naive approaches.
(DeMiguel, Garlappi, and Uppal 2007) run simulations on all-equity investment universes. To provide what may be more practical insights, we also run simulations on a universe of global asset classes that derive their returns from diverse risk sources, such as regional equity indexes, global bonds, and commodities.
Specifically, we evaluate the performance of naive versus optimized portfolios on the following data sets, which are all available at daily scale:
- 10 U.S. market-cap weighted industry portfolios from the Ken French data library
- 25 U.S. market-cap weighted equity factor portfolios sorted on size and book-to-market (i.e. value) from the Ken French data library
- 38 U.S. market-cap weighted sub-industry portfolios from the Ken French data library
- 49 U.S. market-cap weighted sub-industry portfolios from the Ken French data library
- 12 global asset classes from multiple sources2
We form portfolios at the end of each quarter, with a one day delay between calculating optimal portfolio weights and trading.
(DeMiguel, Garlappi, and Uppal 2007) tested a variety of portfolio formation methods including long-short and long-only versions of mean-variance and Minimum Variance optimizations. They also tested different types of shrinkage methods to manage estimation error.
We will follow a similar process, but we will impose long-only, sum-to-one constraints for all optimizations, and use rolling 252 day (i.e. one trading year) sample covariances without any shrinkage methods. The long-only constraint is in recognition of the fact that practitioners are aware of the instability of unconstrained optimization. We will address shrinkage methods in a later article when we discuss more robust optimization methods.
For our simulations, we will compare the performance of naive (equal weighted and market capitalization weighted) methods to portfolios formed using the following optimizations, all of which are long-only constrained (w>0), with weights that sum to 1 ![]()
Optimizations
Note that all but one of the optimization descriptions below were described in our whitepaper on portfolio optimization, and are repeated here for convenience only. If you are familiar with the specifications and optimality equivalence conditions for these optimizations from the whitepaper you are encouraged to skip ahead to the description of the Hierarchical Minimum Variance optimization.
Minimum Variance
If all investments have the same expected return independent of risk, investors seeking maximum returns for minimum risk should concentrate exclusively on minimizing risk. This is the explicit objective of the minimum variance portfolio.
![]()
where ![]() is the covariance matrix.
is the covariance matrix.
(Haugen and Baker 1991) proposed dispensing with any relationship between risk and return, at least for equities. Their paper was one of the first to demonstrate that stock returns are not well explained by beta. In fact, they observed a negative relationship between returns and volatility.
In the face of a spurious link between risk and return, (Haugen and Baker 1991) suggested that a regularly reconstituted long-only Minimum Variance portfolio might dominate the captitalization weighted portfolio for stocks.
Maximum Diversification
(Choueifaty and Coignard 2008) proposed that markets are risk-efficient, such that investments will produce returns in proportion to their total risk, as measured by volatility. This differs from CAPM, which assumes returns are proportional to non-diversifiable (i.e. systematic) risk. Choueifaty et al. described their method as Maximum Diversification (Maximum Diversification), for reasons that will become clear below.
Consistent with the view that returns are directly proportional to volatility, the Maximum Diversification optimization substitutes asset volatilities for returns in a maximum Sharpe ratio optimization, taking the following form.
![]()
where ![]() and reference a vector of volatilities, and the covariance matrix, respectively.
and reference a vector of volatilities, and the covariance matrix, respectively.
DBC ETF extended with Deutsche Bank Liquid Commodity Index, RWO ETF extended with Cohen & Steers Global Realty Shares,Inc. Class I, GLD ETF extended with spot gold in USD.
Note that the optimization seeks to maximize the ratio of the weighted average volatility of the portfolio’s constituents to total portfolio volatility. This is analagous to maximizing the weighted average return, when return is directly proportional to volatility.
An interesting implication, explored at length in a follow-on paper by (Choueifaty, Froidure, and Reynier 2012) is that the ratio maximized in the optimization function quantifies the amount of diversification in the portfolio. This is quite intuitive.
The volatility of a portfolio of perfectly correlated investments would be equal to the weighted sum of the volatilities of its constituents, because there is no opportunity for diversification. When assets are imperfectly correlated, the weighted average volatility becomes larger than the portfolio volatility in proportion to the amount of diversification that is available.
The Diversification Ratio, which is to be maximized, quantifies the degree to which the portfolio risk can be minimized through strategic placement of weights on diversifying (imperfectly correlated) assets.
Maximum Decorrelation
Maximum Decorrelation described by (Christoffersen et al. 2010) is closely related to Minimum Variance and Maximum Diversification, but applies to the case where an investor believes all assets have similar returns and volatility, but heterogeneous correlations. It is a Minimum Variance optimization that is performed on the correlation matrix rather than the covariance matrix. W
Interestingly, when the weights derived from the Maximum Decorrelation optimization are divided through by their respective volatilities and re-standardized so they sum to 1, we retrieve the Maximum Diversification weights. Thus, the portfolio weights that maximize decorrelation will also maximize the Diversification Ratio when all assets have equal volatility and maximize the Sharpe ratio when all assets have equal risks and returns.
The Maximum Decorrelation portfolio is found by solving for:
![]()
where A is the correlation matrix.
Risk Parity
Both the Minimum Variance and Maximum Diversification portfolios are mean-variance efficient under intuitive assumptions. Minimum Variance is efficient if assets have similar returns while Maximum Diversification is efficient if assets have similar Sharpe ratios. However, both methods have the drawback that they can be quite concentrated in a small number of assets. For example, the Minimum Variance portfolio will place disproportionate weight in the lowest volatility asset while the Maximum Diversification portfolio will concentrate in assets with high volatility and low covariance with the market. In fact, these optimizations may result in portfolios that hold just a small fraction of all available assets.
There are situations where this may not be preferable. Concentrated portfolios also may not accommodate large amounts of capital without high market impact costs. In addition, concentrated portfolios are more susceptible to mis-estimation of volatilities or correlations.
These issues prompted a search for heuristic optimizations that meet similar optimization objectives, but with less concentration. The equal weight and capitalization weight portfolios are common examples of this, but there are other methods that are compelling under different assumptions.
Inverse Volatility and Inverse Variance
When investments have similar expected Sharpe ratios, and an investor cannot reliably estimate correlations (or we can assume correlations are homogeneous), the optimal portfolio would be weighted in proportion to the inverse of the assets’ volatilities. When investments have similar expected returns (independent of volatility) and unknown correlations, the Inverse Variance portfolio is mean-variance optimal. Note that the Inverse Volatility portfolio is consistent with the Maximum Diversification portfolio, and the Inverse Variance portfolio approximates a Minimum Variance portfolio, when all investments have identical pairwise correlations.
The weights for the inverse volatility and inverse variance portfolios are found by:
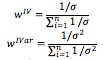
where ![]() is the vector of asset volatilities and is the vector of asset variances.
is the vector of asset volatilities and is the vector of asset variances.
Equal Risk Contribution
(Maillard, Roncalli, and Teiletche 2008) described the Equal Risk Contribution optimization, which is satisfied when all assets contribute the same volatility to the portfolio. It has been shown that the Equal Risk Contribution portfolio is a compelling balance between the objectives of the equal weight and Minimum Variance portfolios. It is also a close cousin to the Inverse Volatility portfolio, except that it is less vulnerable to the case where assets have vastly different correlations.
The weights for the Equal Risk Contribution Portfolio are found through the following convex optimization, as formulated by (Spinu 2013):
![]()
where ![]() is the covariance matrix.
is the covariance matrix.
The Equal Risk Contribution portfolio will hold all assets in positive weight, and is mean-variance optimal when all assets are expected to contribute equal marginal Sharpe ratios (relative to the Equal Risk Contribution portfolio itself). Thus, optimality equivalence relies on the assumption that the Equal Risk Contribution portfolio is macro-efficient. It has been shown that the portfolio will have a volatility between that of the Minimum Variance Portfolio and the Equal Weight portfolio.
Hierarchical Minimum Variance
(Lopez de Prado 2016) proposed a novel portfolio construction method that he labeled “Hierarchical Risk Parity”. The stated purpose of this new method was to “address three major concerns of quadratic optimizers in general and Markowitz’s CLA3 in particular: Instability, concentration and underperformance.”
Aside from the well-known sensitivity of mean-variance optimization to errors in estimates of means, De Prado recognized that traditional optimizers are also vulnerable because they require the action of matrix inversion and determinants, which can be problematic when matrices are poorly conditioned. Matrices with high condition numbers are numerically unstable, and can lead to undesirably high loadings on economically insignificant factors.
(Lopez de Prado 2016) asserts that the correlation structure contains ordinal information, which can be exploited by organizing the assets into a hierarchy. The goal of Hierarchical Risk Parity is to translate/reorganize the covariance matrix such that it is as close as possible to a diagonal matrix, without altering the covariance estimates. The minimum variance portfolio of a diagonal matrix is the inverse variance portfolio. For this reason, we describe the method as Hierarchical Minimum Variance. We explain many of these concepts in much greater detail in a follow-on article4.
Review of (DeMiguel, Garlappi, and Uppal 2007)
We now proceed to discuss the results of a paper, “Optimal Versus Naive Diversification: How Inefficient is the 1/N Portfolio Strategy?” by (DeMiguel, Garlappi, and Uppal 2007), which is commonly cited to dismiss optimization based methods. According to the paper, the authors were motivated by a desire to “understand the conditions under which mean-variance optimal portfolio models can be expected to perform well even in the presence of estimation risk.” They emphasize that the purpose of their study “is not to advocate the use of the 1/N heuristic as an asset-allocation strategy, but merely to use it as a benchmark to assess the performance of various portfolio rules proposed in the literature.”
While we are committed to revisiting the analysis from (DeMiguel, Garlappi, and Uppal 2007), we question the generality of the paper for several important reasons. First, the authors chose to specify their models in ways that, while technically precise, violate most common-sense practices in portfolio management. In addition, they chose to run their empirical analyses on universes that are almost perfectly designed to confound optimization-based methods.
Confusing methodology
The specification issues relate primarily to the way the authors measure means and covariances for optimization. For example, they run simulations that form optimal portfolios monthly based on rolling 60- and 120-month estimation windows.
This is curious for a number of reasons. First, the authors do not cite evidence that investors use these estimation windows to form optimal portfolios in practice. Thus, there is no reason to believe their methodology represents a meaningful use case for optimization.
Second, the authors provide no evidence or theory for why estimates from 60 and 120 month windows should be informative about next months’ returns. In fact, they performed their analysis on equity portfolios, and there is evidence that equity portfolios are mean-reverting over long horizons.
The primary case for the existence of long term mean reversion was made in two papers published in 1988, one by (Poterba and Summers 1988), and the other published by (Fama and French 1988). These papers conclude that for period lengths of between 3 and 5 years (i.e. 36 an 60 months), long-term mean reversion was present in stock market returns between 1926 and 1985. Three-year returns showed a negative correlation of 25%, while 5-year returns showed a negative correlation of 40%.
If returns over the past 5-10 years are mean-reverting over the horizon chosen by (DeMiguel, Garlappi, and Uppal 2007) to estimate portfolio means, we shoud expect performance of optimal portfolios to be disappointing, as the return forecasts for portfolio optimization would be above average for periods that should actually produce below-average returns, and vice versa.
The authors also highlight that the estimation of covariances is confounded by sparseness issues on large universes. Specifically, the covariance matrix will be ill conditioned if the length of the estimation window is smaller than the dimension of the matrix. To find the optimal weights for 500 securities would require at least 500 data points per security. At monthly granularity, this would require 42 years of data, while we would need 10 years of weekly data.
However, the test datasets used in the paper are also available at daily granularity. At daily frequency, the covariance matrix is appropriately conditioned, and optimization can be performed on, 500 securities with less than two years of data. One is left to wonder why the authors used data at monthly frequency when daily data were available.
Homogeneous investment universes
The investment universes used to compare the performance of naive versus optimal diversification methods seem poorly chosen based on the authors stated purpose to “understand the conditions under which mean-variance optimal portfolio models can be expected to perform well.” The authors conducted their analysis on investment universes composed exclusively of equity portfolios. Clearly, equity portfolios are dominated by a single source of risk, equity beta, and provide few opportunities for diversification.
(DeMiguel, Garlappi, and Uppal 2007) concede this issue directly in the paper:
… the 1/N rule performs well in the datasets we consider [because] we are using it to allocate wealth across portfolios of stocks rather than individual stocks. Because diversified portfolios have lower idiosyncratic volatility than individual assets, the loss from naive as opposed to optimal diversification is much smaller when allocating wealth across portfolios. Our simulations show that optimal diversification policies will dominate the 1/N rule only for very high levels of idiosyncratic volatility [Emphasis ours].
Idiosyncratic volatility is simply the volatility of the residuals after the asset returns are regressed on the dominant systematic risk factor. In the case of equity portfolios like the sector, industry and factor portfolios under investigation by (DeMiguel, Garlappi, and Uppal 2007), these are the residuals on equity beta. If most of the variance for the test universes is explained by equity beta, there will be very little idiosyncratic volatility, and very little opportunity for diversification.
Few opportunities for diversification
One way to determine the amount of idiosyncratic risk in a universe of assets is to use Principal Component Analysis (PCA). PCA is a tool to identify the underlying independent (i.e. uncorrelated) sources of risk, or principal components, of the investments.
The results of PCA are eigenvalues, , which describe the amount of total variance explained by each principal component, and the eigenvectors , which describe the sensitivities or “betas” of each asset to each principal component. There are always the same number of eigenvalues and eigenvectors as investments, so a universe of ten investments will be decomposed into ten eigenvectors with associated eigenvalues.
The principal components are ordered so that the first component is the one that explains the most variance. For a universe of equities, it is held that the first principal component represents market beta. Thus, the first eigenvalue quantifies the amount of total portfoio variance explained by market beta.
All of the other principal components represent directions of risk that are independent of market beta. So the total amount of idiosyncratic variance in a universe of assets is equal to .5
We examined the amount of idiosyncratic risk available to provide diversification for each universe that we targeted for investigation in Figure 1. We also show a decomposition for an even more diverse universe of major futures markets to highlight the opportunity for diversification outside of conventional asset classes. The chart shows the amount of idiosyncratic risk available for diversification, so lower bars imply less diversification opportunity.
Figure 1: Idiosyncratic risk in different investment universes.
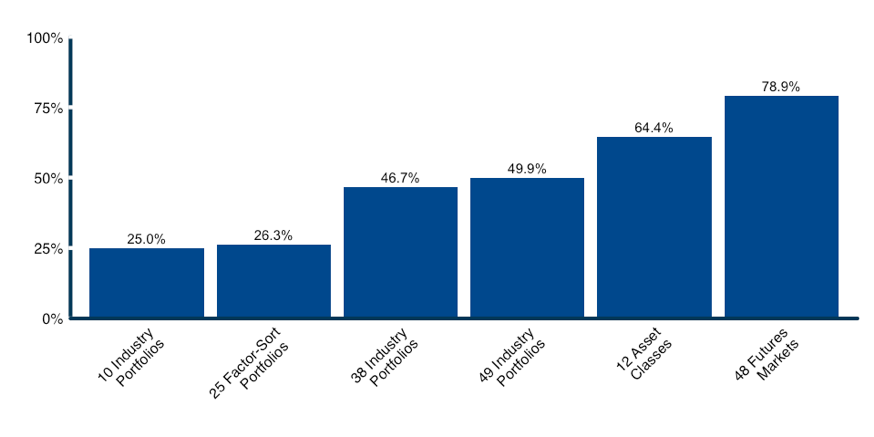
Source: Calculations by ReSolve Asset Management. Data for industries and portfolios sorted on size and book-to-market from Ken French database. Data for country equity indices from Global Financial Data. Asset class data from S&P Dow Jones Indices. Futures data from CSI. Idiosyncratic risk is calculated as 1 - the proportion of total variance explained by the first principal component.
You can see that about three-quarters of the variance in the industry and factor sort universes is explained by the first principal component, which represents U.S. equity beta. Just one quarter of the risk is idiosyncratic risk, which might be used to enhance diversification.
In contrast, about two-thirds and four-fifths of the risk in the asset class and futures universe, respectively, are derived from sources other than the first principal component. This leaves much more idiosyncratic variance for optimization methods to make best use of diversification opportunities.
Number of independent “bets”
To understand just how little opportunity for diversification there is in (DeMiguel, Garlappi, and Uppal 2007)’s choices of investment universes, we found it useful to quantify the number of uncorrelated sources of return (i.e. independent bets) that are available in each group of investments.
Recall that (Choueifaty and Coignard 2008) showed that the Diversification Ratio of a portfolio is the ratio of the weighted sum of asset volatilities to the portfolio volatility after accounting for diversification.
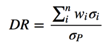
This is intuitive because, if all of the assets in the portfolio are correlated, the weighted sum of their volatilities would equal the portfolio volatility, and the Diversification Ratio would be 1. As the assets become less correlated, the portfolio volatility will decline due to diversification, while the weighted sum of constituent volatilities will remain the same, causing the ratio to rise. At the point where all assets are uncorrelated (zero pairwise correlations), every asset in the portfolio represents an independent bet.
Consider a universe of ten assets with homogeneous pairwise correlations. Figure 2 plots how the number of independent bets available declines as pairwise correlations rise from 0 to 1. Note when correlations are 0, there are 10 bets, as each asset is responding to its own source of risk. When correlations are 1, there is just 1 bet, since all assets are explained by the same source of risk.
Figure 2: Number of Independent Bets expressed with an equally weighted portfolio of 10 assets with equal volatility as a function of average pairwise correlations.
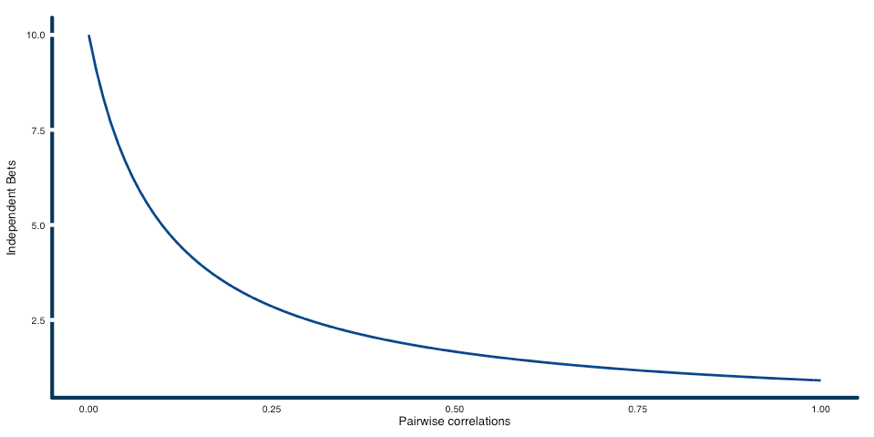
Source: ReSolve Asset Management. For illustrative purposes only.
(Choueifaty, Froidure, and Reynier 2012) demonstrate that the number of independent risk factors in a universe of assets is equal to the square of the Diversification Ratio of the Most Diversified Portfolio.
Taking this a step further, we can find the number of independent (i.e. uncorrelated) risk factors that are ultimately available for diversification within a universe of assets by first solving for the weights that satisfy the Most Diversified Portfolio. Then we take the square of the Diversification Ratio of this portfolio to produce the number of unique directions of risk, if we maximize the diversification opportunity.
We apply this approach to calculate the number of independent sources of risk that are available to investors in each of our test universes. Using the full data set available for each universe, we solve for the weights of the Maximum Diversification portfolios, and calculate the square of the Diversification Ratios. We find that the 10 industry portfolios; 25 factor portfolios; 38 sub-industry portfolios; and 49 sub-industry portfolios produce 1.4, 1.9, 2.8, and 3.3 unique sources of risk, respectively. Results are summarized in Figure 3.
These are rather astonishing results. Across 10 industry portfolios, and 25 factor portfolios, there are less than 2 uncorrelated risk factors at play. When we expand to 36 and 49 sub-industries, we achieve less than 3 and 4 factors, respectively.
To put this in perspective, we also calculated the number of independent factors at play in our test universe of 12 asset classes, and find 5 independent bets. To take it one step further, we also analyzed the independent bets available to 48 major futures markets across equity indexes, bonds, and commodities, and found 13.2 uncorrelated risk factors.
Figure 3: Number of independent risk factors present in the investment universe.
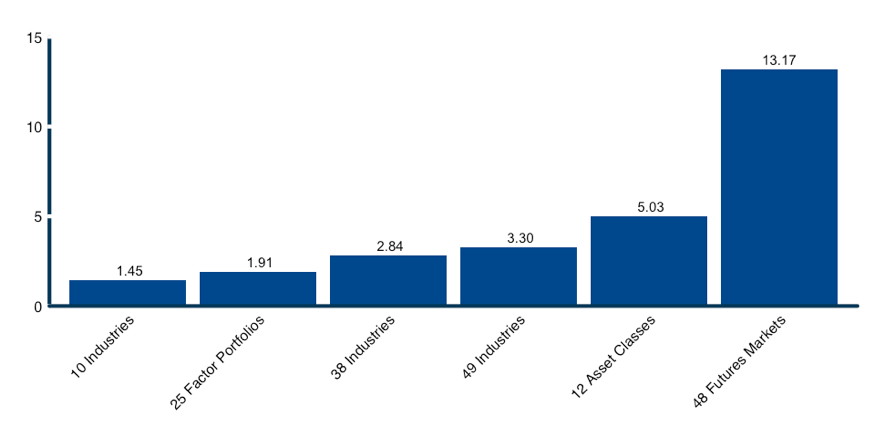
Source: Calculations by ReSolve Asset Management. Data for industries and portfolios sorted on size and book-to-market from Ken French database. Data for country equity indices from Global Financial Data. Asset class data from S&P Dow Jones Indices. Futures data from CSI. Number of independent bets is equal to the square of the Diversification Ratio of the Most Diversified Portfolio formed using pairwise complete correlations over the entire dataset.
Forming hypotheses from the Optimization Machine
The Optimization Machine was created to help investors choose the most appropriate optimization for any investment universe given the properties of the investments and the investor’s beliefs. Specifically, the Optimization Machine Decision Tree leads investors to the portfolio formation method that is most likely to produce mean-variance optimal portfolios given active views on some or all of volatilities, correlations, and/or returns, and general relationships between risk and return, if any.
One of the most important qualities investors should investigate is the amount of diversification available relative to the number of assets. If the quantity of available diversification is small relative to the number of assets, the noise in the covariance matrix is likely to dominate the signal.
We’ll call the ratio of the number of independent bets to the number of assets in an investment universe the “Quality Ratio”. The “Quality Ratio” is a good proxy for the amount of diversification “signal to noise” in the investment universe. When the Quality Ratio is high we would expect optimization methods to dominate naive methods. When it is low, investors should expect only a very small boost in risk-adjusted performance from using more sophisticated techniques.
For example the Quality Ratio of the universe of 10 industry portfolios is 0.12 while the Quality Ratio of the universe of 49 sub-industries is 0.07. Compare these to the Quality Ratio of our asset class universe at 0.42.
Figure 4: Quality Ratio: Number of independent bets/number of assets.
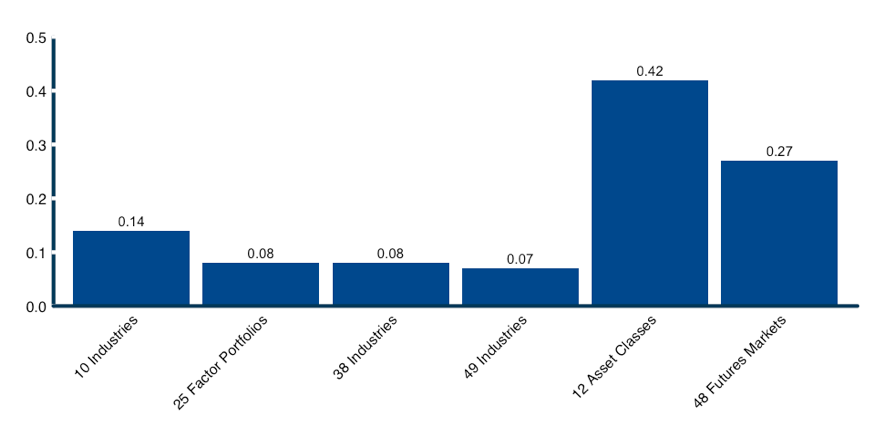
Source: Calculations by ReSolve Asset Management. Data for industries and portfolios sorted on size and book-to-market from Ken French database. Data for country equity indices from Global Financial Data. Asset class data from S&P Dow Jones Indices. Futures data from CSI. Number of independent bets is equal to the square of the Diversification Ratio of the Most Diversified Portfolio formed using pairwise complete correlations over the entire dataset. Quality ratio is number of independent bets / number of assets.
The Quality Ratio helps inform expectations about how well optimization methods, in general, can compete against naive methods. For universes with low Quality Ratios, we would expect naive methods to dominate optimization, while universes with relatively high Quality Ratios are likely to benefit from optimal diversification.
Where a high Quality Ratio would prompt an investor to choose optimization, the next step is to choose the optimization method that is most likely to achieve mean-variance efficiency. The Optimization Decision Tree is a helpful guide, as it prompts questions about which portfolio parameters can be estimated, and the expected relationships between risk and return. The answers to these questions lead directly to an appropriate method of portfolio formation.
Most of the branches of the Optimization Decision Tree lead to heuristic optimizations that obviate the need to estimate individual asset returns by expressing returns as a function of different forms of risk. For example, Maximum Diversification optimization expresses the view that returns are directly and linearly proportional to volatility, while Minimum Variance optimization expresses the view that investments have the same expected return, regardless of risk. Thus, these optimizations do not require any estimates of means, and only require estimates of volatilities or covariances.
This is good, because (Chopra and Ziemba 1993) demonstrate that optimization is much more sensitive to errors in sample means than to errors in volatilities or covariances. The authors show that for investors with relatively high risk tolerances, errors in mean estimates are 22x as impactful as errors in estimates of covariances. For less risk tolerant investors the relative impact of errors in sample means rises to 56x that of errors in covariances. This doesn’t mean investors should always eschew optimizations with active views on returns; rather, that investors should take steps to minimize the error term in general. We discuss this concept at length in future articles.
For now, we will constrain our choices of optimization to common risk-based methods, such as Minimum Variance, Maximum Diversification, and Risk Parity. The optimizations are useful if we assume we can’t achieve any edge with better estimates of return. Later, we will explore how one might incorporate systematic active views, such as those rendered by popular factor strategies like momentum, value, and trend.
Let’s use the Optimization Machine to infer which portfolio formation method should produce the best results for each investment universe. To be specific, we want to forecast which optimization method is most likely to produce the highest Sharpe ratio.
Regardless which optimization is chosen, the the magnitude of outperformance for optimization relative to equal weighting will depend largely on the Quality Ratio of the investment universe. The industry and factor equity portfolios have low Quality Ratios, and should produce a marginal improvement over the equal weight approach. The asset class universe has a higher Quality Ratio, suggesting that we should see more substantial outperformance from optimization relative to equal weighting.
Stock industry and factor portfolios
Recall from our paper, “The Optimization Machine: A General Framework for Portfolio Choice” that historically, the returns to stocks are either unrelated or inversely related to both beta and volatility. All risk based optimizations rely on either a positive relationship, or no relationship, between risk and return because an inverse relationship violates the foundational principles of financial economics (specifically rational utility theory), so we will assume the returns to stock portfolios of industries and factor sorts are all equal, and independent of risk.
Following the Portfolio Optimization Decision Tree, we see that the equal weight portfolio is mean-variance optimal if assets have the same expected returns, and if they have equal volatilities and correlations. The Minimum Variance portfolio is also mean-variance optimal if assets have the same expected returns, but the optimization also accounts for differences in expected volatilies and heterogeneous correlations.
Ex ante, the Minimum Variance portfolio should outperform the equal weight portfolio if covariances are heterogeneous (i.e. unequal), and the covariances observed over our estimation window (rolling 252 day returns) are reasonably good estimates of covariances over the holding period of the portfolio (one calendar quarter in our case).
It is also a useful exercise to consider which method is most likely to produce the worst results. Given that the empirical relationship between risk and return has been negative, we might expect optimizations that are optimal when the relationship is positive to produce the worst results. The Maximum Diversification optimization is specifically optimal when returns are directly proportional to volatility. It makes sense that this portfolio would lag the performance of the equal weight and Minimum Variance portfolios, which assume no relationship.
Asset class portfolio
When performance is averaged across the four economic regimes described by combinations of inflation and growth shocks, stocks and bonds have equal historical Sharpe ratios6. The historical Sharpe ratio for commodities is about half what was observed for stocks and bonds. However, given that our sample size consists of just a handful of regimes since 1970, we are reluctant to reject the practical assumption that the true Sharpe ratio of a portfolio of diversified commodities is consistent with that of stocks and bonds.
If we assume stocks, bonds, and commodities have similar Sharpe ratios the Optimization Machine Decision Tree suggests the mean-variance optimal portfolio can be found using the Maximum Diversification optimization. The Risk Parity portfolio should also perform well, as it is optimal when assets have equal marginal Sharpe ratios to the equal risk contribution portfolio.
The equal weight and Minimum Variance portfolios are likely to produce the weakest Sharpe ratios, because their associated optimality conditions are most likely to be violated. The major asset classes are generally uncorrelated, while the sub-classes (i.e. regional indexes) are more highly correlated with one another, so the universe should have heterogeneous correlations. In addition, bonds should have much lower volatility than other assets. Lastly, the individual asset returns should be far from equal, since the higher risk assets should have higher returns.
With our hypotheses in mind, let’s examine the results of simulations.
Simulation results
We run simulations on each of our target investment universes to compare the simulated performance of portfolios formed using naive and optimization based methods. Where volatility or covariance estimates are required for optimization, we use the past 252 days to form our estimates. We perform no shrinkage other than to constrain portfolios to be long-only with weights that sum to 100%. Portfolios are rebalanced quarterly.
For illustrative purposes, Figure 5 describes the growth of $1 for simulations on our universe of 25 portfolios sorted on price and book-to-market. Consistent with the ready availability of leverage, and for easy comparison, we have scaled each portfolio to the same ex-post volatility as the market-capitalization weighted portfolio7. We assume annual leverage costs equal to the 3-month T-bill rate plus one percent. Scaled to equal volatility, portfolios formed using Minimum Variance have produced the best performance over the period 1927 - 2017.
Figure 5: Growth of $1 for naive versus robust portfolio optimizations, 25 factor portfolios sorted on size and book-to-market, 1927 - 2018
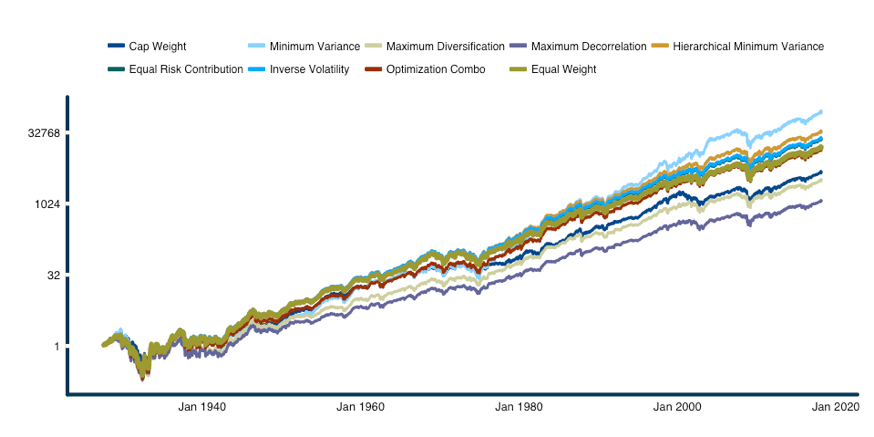
Source: ReSolve Asset Management. Simulated results. Portfolios formed quarterly based on trailing 252 day returns for industries, factor portfolios, and monthly for asset classes. Results are gross of transaction related costs. For illustrative purposes only.
Table 1 summarizes the Sharpe ratios of each optimization method applied to each universe.
Table 1: Performance statistics: naive versus robust portfolio optimizations. Industry and factor simulations from 1927 - 2017. Asset class simulations from 1990 - 2017.
|
10 Industries |
25 Factor Sorts |
38 Industries |
49 Industries |
12 Asset Classes |
|
|
Average of Asset Sharpe Ratios |
0.44 |
0.46 |
0.37 |
0.37 |
0.34 |
|
Cap Weight |
0.44 |
0.44 |
0.44 |
0.44 |
|
|
Equal Weight |
0.50 |
0.51 |
0.49 |
0.50 |
0.54 |
|
Minimum Variance |
0.53 |
0.62 |
0.58 |
0.55 |
0.60 |
|
Maximum Diversification |
0.50 |
0.41 |
0.55 |
0.53 |
0.75 |
|
Maximum Decorrelation |
0.50 |
0.35 |
0.49 |
0.46 |
0.65 |
|
Hierarchical Minimum Variance |
0.51 |
0.56 |
0.55 |
0.55 |
0.64 |
|
Equal Risk Contribution |
0.51 |
0.54 |
0.54 |
0.54 |
0.69 |
|
Inverse Volatility |
0.51 |
0.54 |
0.52 |
0.52 |
0.67 |
|
Optimization Combo |
0.52 |
0.51 |
0.56 |
0.55 |
0.69 |
Source: ReSolve Asset Management. Simulated results. Portfolios formed quarterly based on trailing 252 day returns for industries, factor portfolios, and monthly for asset classes. Results are gross of transaction related costs. For illustrative purposes only.
Discussion of simulation results
The first things to notice is that all methods outperformed the market cap weighted portfolio with a few notable exceptions: the Maximum Diversification portfolio underperformed the market cap weighted portfolio on the factor sort universe.
Stocks
This should not be surprising. The market cap weighted portfolio is mean-variance optimal if returns to stocks are explained by their to the market, so that stocks with higher have commensurately higher returns. However, we showed in our whitepaper on portfolio optimization that investors are not sufficiently compensated for bearing extra risk in terms of market. Thus, investors in the market cap weighted portfolio are bearing extra risk, which is not compensated.
The evidence confirmed our hypothesis that the Minimum Variance portfolio should produce the best risk-adjusted performance on the equity oriented universes. Hierarchical Minimum Variance was also competitive.
The Optimization Machine Decision Tree also indicated that the Maximum Diversification strategy should perform worst on the equity universes because of the flat (or even negative) empirical relationship between risk and return for stocks. Indeed, Maximum Diversification lagged the other optimizations in some simulations. However, it produced better results than Inverse Volatility and Equal Risk Contribution methods in many cases, and dominated equal weight portfolios for 38 and 49 industry simulations.
Asset Classes
Our belief that diversified asset classes should have equal long-term Sharpe ratios led us to hypothesize that the Maximum Diversification portfolio should dominate in the asset class universe. We expected the equal weight and Minimum Variance strategies to underperform. These predictions played out in simulation. The Equal Risk Contribution and Inverse Volatility weighted approaches were also competitive, which suggests the assumption of constant correlations may not be far from the mark.
In addition to publishing the results for each method of portfolio choice, we also published the results for a portfolio that averaged the weights at each period across all of the optimization strategies. For all universes except the factor sort universe, the unbiased average of all optimizations (including the least optimal strategy) outperformed the naive equal weight method.
Tests of significance
While it’s true that the appropriate optimization based approaches produced better results than equal weighting for every universe, it’s useful to examine whether the results are statistically signficant. After all, the performance boosts observed for the best optimization methods are not very large.
To determine whether the results are economically meaningful or simply artifacts of randomness, we performed a block bootstrap test of Sharpe ratios. Specifically, we randomly sampled blocks of four quarters of returns (12 monthly returns for the asset class universe), with replacement, to create 10,000 potential return streams for each strategy.
Each draw contained a sample of equal weight returns alongside returns to the target optimal strategy, with the same random date index. Each sample was the same length as the original simulation.
We then compared the Sharpe ratio of each sample from equal weight returns to the Sharpe ratio of the sample of optimal weight returns. The values in Table 2 represent the proportion of samples where the Sharpe ratio for samples of equal weight returns exceeded the Sharpe ratio for samples of optimal strategy returns. As such, they are analagous to traditional p-values, where p is the probability that the optimal strategy outperformed due to random chance.
Table 2: Pairwise probabilities that the Sharpe ratios of optimization based strategies are less than or equal to the Sharpe ratio of the equal weight strategy.
|
10 Industries |
25 Factor Sorts |
38 Industries |
49 Industries |
12 Asset Classes |
|
|
Minimum Variance |
0.03 |
0.00 |
0.00 |
0.06 |
0.03 |
|
Maximum Diversification |
0.07 |
1.00 |
0.01 |
0.44 |
0.01 |
|
Maximum Decorrelation |
0.19 |
1.00 |
0.25 |
0.94 |
0.01 |
|
Hierarchical Minimum Variance |
0.01 |
0.00 |
0.00 |
0.00 |
0.07 |
|
Equal Risk Contribution |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
|
Inverse Volatility |
0.00 |
0.00 |
0.00 |
0.00 |
0.00 |
|
Optimization Combo |
0.00 |
0.97 |
0.00 |
0.08 |
0.00 |
Source: ReSolve Asset Management. Simulated results. Portfolios formed quarterly based on trailing 252 day returns for industries, factor portfolios, and monthly for asset classes. Results are gross of transaction related costs. For illustrative purposes only.
This analysis yields some surprising results. While the Minimum Variance strategy produced the highest sample Sharpe ratio for all of the equity oriented universes, Risk Parity based methods like Equal Risk Contribution and Inverse Volatility were even more dominant from a statistical standpoint. The Hierarchical Minimum Variance approach also demonstrated a high degree of statistical robustness.
For the asset class universe, all but the Hierarchical Minimum Variance portfolio outperformed the equal weight portfolio on a statistically significant basis. And the Hierarchical Minimum Variance portfolio outperformed the equal weight portfolio 93% of the time. This further validates the importance of optimization when the universe of assets has diverse volatility and correlation features.
Risk Parity methods are more likely to dominate equal weight portfolios because they exhibit a smaller amount of active risk relative to the equal weight portfolio. However, while the Risk Parity portfolios might outperform the equal weight portfolios slightly more frequently on a relative basis, they are likely to more frequently underperform Minimum Variance and Maximum Diversification, for equity and asset class universes respectively, on an absolute basis.
Summary and Next Steps
Many investment professionals are under the misapprehension that portfolio optimization is too noisy to be of practical use. This myth is rooted in a few widely cited papers that purport to show that portfolio optimization fails to outperform naive methods.
The goal of this article was to illustrate how the Portfolio Optimization Machine is a useful framework to identify which optimization method should be most appropriate for a given investment universe. We used the Optimization Machine along with data and beliefs to form hypotheses about optimal portfolio choice for a variety of investment universes. Then we proceeded to test the hypotheses by simulating results on live data.
The choices invoked by the Portfolio Optimization Machine produced superior results. Both naive and optimal methods dominated the market cap weighted portfolio. Optimization based methods dominated naive equal weighted methods in most cases, except where an optimization expressed relationships between risk and return that were precisely converse to what was observed in the historical record. For example, Maximum Diversification expresses a positive relationship between return and volatility, while stocks have historically exhibited a flat, or perhaps even inverted relationship. We should therefore not be surprised to learn that Maximum Diversification underperformed the equal weight portfolio when applied in some equity oriented universes.
While optimization based methods rivaled the performance of naive methods for the cases investigated in this paper, we acknowledge that our test cases may not be representative of real-world challenges faced by many portfolio managers. Many problems of portfolio choice involve large numbers of securities, with high average correlations. Investors will also often demand constraints on sector risk, tracking error, factor exposures, and portfolio concentration. Other investors may run long/short portfolios, which introduce much higher degrees of instability.
We are sympathetic to the fact that most finance practitioners are not trained in numerical methods. While portfolio optmization is covered in the CFA and most MBA programs, the topic is limited to the most basic two-asset case of traditional mean-variance optimization with known means and covariances. Of course, this doesn’t resemble real world problems of portfolio choice in any real way.
In future articles we will explore more challenging problems involving lower quality investment universes with more typical constraints. We will dive more deeply into some of the mathematical challenges with optimization, and present novel solutions backed up by robust simulationsdf. Later, we will describe how to incorporate dynamic active views on asset returns informed by systematic factors, which we call “Adaptive Asset Allocation.”
References
Bun, Joël, Jean-Philippe Bouchaud, and Marc Potters. 2016. “Cleaning large correlation matrices: tools from random matrix theory.” https://arxiv.org/abs/1610.08104.
Chopra, Vijay K., and William T. Ziemba. 1993. “The Effect of Errors in Means, Variances, and Covariances on Optimal Portfolio Choice.” Journal of Portfolio Management 19 (2): 6–11.
Choueifaty, Yves, and Yves Coignard. 2008. “Toward Maximum Diversification.” Journal of Portfolio Management 35 (1). http://www.tobam.fr/wp-content/uploads/2014/12/TOBAM-JoPM-Maximum-Div-2008.pdf: 40–51.
Choueifaty, Yves, Tristan Froidure, and Julien Reynier. 2012. “Properties of the Most Diversified Portfolio.” Journal of Investment Strategies 2 (2). http://www.qminitiative.org/UserFiles/files/FroidureSSRN-id1895459.pdf: 49–70.
Christoffersen, P., V. Errunza, K. Jacobs, and X. Jin. 2010. “Is the Potential for International Diversification Disappearing?” Working Paper. https://ssrn.com/abstract=1573345.
DeMiguel, Victor, Lorenzo Garlappi, and Raman Uppal. 2007. “Optimal Versus Naive Diversification: How Inefficient is the 1/N Portfolio Strategy?” http://faculty.london.edu/avmiguel/DeMiguel-Garlappi-Uppal-RFS.pdf: Oxford University Press.
Fama, Eugene, and Kenneth French. 1988. “Permanent and Temporary Components of Stock Prices.” Journal of Political Economy 96. https://teach.business.uq.edu.au/courses/FINM6905/files/module-2/readings/Fama: 246–73.
Haugen, R., and N. Baker. 1991. “The Efficient Market Inefficiency of Capitalization-Weighted Stock Portfolios.” Journal of Portfolio Management 17. http://dx.doi.org/10.3905/jpm.1991.409335: 35–40.
Lopez de Prado, Marcos. 2016. “Building Diversified Portfolios that Outperform Out of Sample.” Journal of Portfolio Management 42 (4): 59–69.
Maillard, Sebastien, Thierry Roncalli, and Jerome Teiletche. 2008. “On the properties of equally-weighted risk contributions portfolios.” http://www.thierry-roncalli.com/download/erc.pdf.
Poterba, James M., and Lawrence H. Summers. 1988. “Mean Reversion in Stock Prices: Evidence and Implications.” Journal of Financial Economics 22 (1). http://www.nber.org/papers/w2343: 27–59.
Spinu, Florin. 2013. “An Algorithm for Computing Risk Parity Weights.” SSRN. https://ssrn.com/abstract=2297383.
1 This should not be confused with the Quality Ratio from Random Matrix Theory, which is the ratio of variables to number of independent samples. See (Bun, Bouchaud, and Potters 2016)
2 SPY ETF extended with S&P 500 Index, VGK ETF extended with S&P Europe BMI, VPL ETF extended with S&P Asia Pacific BMI, VWO ETF extended with S&P Emerging BMI, IEF ETF extended with S&P US Treasury 7-10 Year TR Index, TLT ETF exteneded with S&P US Treasury Bond 20+ Year TR Index, LTPZ extended with S&P US TIPS 15+ Year Index and PIMCO Real Return Fund, BWX ETF extended with S&P/Citigroup International Treasury Ex-US TR Index and T. Rowe Price International Bond Fund, EMB ETF extended with PIMCO Emerging Markets Bond Fund and T. Rowe Price Emerging Markets Bond Fund, DBC ETF extended with Deutsche Bank Liquid Commodity Index, RWO ETF extended with Cohen & Steers Global Realty Shares,Inc. Class I, GLD ETF extended with spot gold in USD.
3 Critical Line Algorithm
4 For a full description of the method including Python code see this presentation.
5 We are concerned with the directions of risk, rather than the magnitudes of risk. The direction of risk is endogenous to the investments while the magnitude of risk - the volatility - can be scaled up and down by changing the exposure. As a result, we focus our decomposition on the correlation matrix, rather than the covariance matrix.
6 See our paper “The Optimization Machine: A General Framework for Portfolio Choice”
7 “Market” factor plus the risk free rate from Ken French database.
Membership required
Membership is now required to use this feature. To learn more:
View Membership BenefitsSponsored Content
Upcoming Virtual Events View All